Genetics and Data Science
A critical analysis of existing genetic databases is needed to understand which data are lacking. Specifically, the aim is to investigate big transregional databases through the lens of urban environmental factors such as urban density, looking for their impact on well-being and mental health.
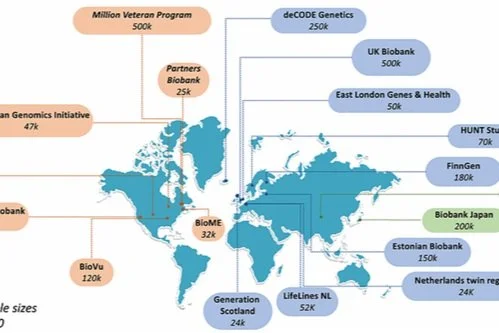
We will analyze some large genetic databases (UK-Biobank, iPsych, Generation Scotland, Estonian Biobank, Finngen, MoBa, Decode, 23andme, Psychiatric Genomics Consortium; see Table 2), with which the applicants collaborate extensively. For some of these databases, raw data access is already in place. In contrast, for most of these, raw data analyses will be performed by local analysts, after which summary statistics will be shared for further investigation.
Generally, we will also investigate these databases for interactive and additive effects of biological risk for various mental health phenotypes (e.g., polygenic risk scores) with environmental factors (population and built density, green spaces, air and noise pollution, extreme weather events). These environmental data will be inferred from variables such as “home locations,” “residential air pollution,” and “residential noise pollution” (examples from the UK-Biobank) in combination with publicly available environmental data. The causality (direction) of these effects (e.g., Is environment influencing mental health? Is genetic predisposition influencing the choice of residence?) will be tested via Mendelian Randomization Analyses.